2022. 3. 11. 15:34ㆍ나혼빅(나혼자빅데이터)/시계열데이터
[시계열 데이터] 01. 시계열 데이터 개요
(시계열데이터 분석을 위한 Datatime Index / 시계열 분석을 위한 판다스 유틸리티 활용)
해당 포스팅은 Udemy(유데미)의 시계열 데이터 분석 with Python(파이썬)을 수강하면서 정리하였습니다.
01. 데이터 설명
- 캐글(Kaggle)의 스타벅스 주식 데이터 활용
- https://www.kaggle.com/hrideshkohli/starbucks
- 총 1006 row, 3 columns('Date', 'Close', 'Volume')으로 구성

- 2015년 1월 2일부터 2018년 12월 31일 까지 스타벅스 종가(Close), 거래량수(Volume)를 나타낸 시계열 데이터
- 현재 일자에 해당하는 ‘Date’ 칼럼은 object 객체 타입으로, 시계열 분석을 위해서는 ‘Datetime’ 객체로 변환시켜줘야함
02. 시계열데이터 분석을 위한 Datetime Index
- 시계열 데이터를 load 해올 때부터, datetime 객체로 변환해주는 것이 데이터 핸들링할 때 편리함
data = pd.read_csv('경로/파일명', index_col='컬럼명', parse_dates=True) - parse_dates = True/False 날짜데이터를 datetime 형태로 변환할지 여부
- 'object' 데이터 타입이었던 'Date' column을 'Datatime' 데이터 타입 Index로 변환
03. 시계열 분석을 위한 판다스 유틸리티 활용
: 시간재조정(resampling), 시간이동(shift),
빈도집계(rolling), 누적집계(Expanding)
3-1. 시간재조정(시간 리샘플링) - resampling
가. resampling 설명
- 시계열 데이터를 특정 시간 단위 구간 별로 재조정하며, 집계함수와 같이 씀
- 샘플링 시, 데이터 양의 증가와 감소에 따라 (1) 업샘플링(up-sampling), (2) 다운샘플링(down-sampling)
(1) 업샘플링(up-sampling) : 시간 구간이 작아지면 데이터 양이 증가함
(2)다운샘플링(down-sampling) : 시간 구간이 커지면 데이터 양이 감소함
나. resampling 인자
- resampling 메서드 안의 rule 인자로 시계열 데이터 빈도/주기 날짜 조정 가능
다. resampling 를 활용한 집계 예
라. resampling을 활용한 월/년 첫 데이터 샘플링 사용자 함수 만들기 / 시각화 해보기
def get_first_day(entry):
if len(entry): #missing data가 아니면
return entry[0]
예) 월 별 첫 데이터 샘플링
예) 연도 별 첫 데이터 샘플링
예) 원 데이터에서 리샘플링하여 구한 월 별 최대값 데이터 시각화
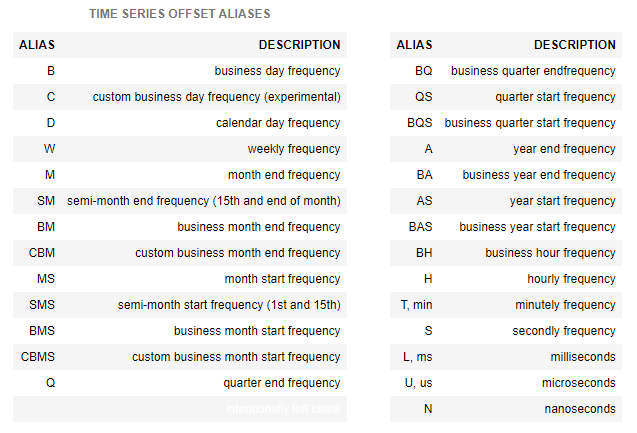
라. 시계열 데이터 빈도/주기와 날짜 (Frequencies and Date Offsets)
3-2. 시간 이동 - shift
가. shift 설명
- 모든 데이터를 위 또는 아래로 시계열 인덱스를 따라 이동 시켜야 할 때
- 지정한 행 수에 대해 전체 인덱스를 이동
나. shift 사용법
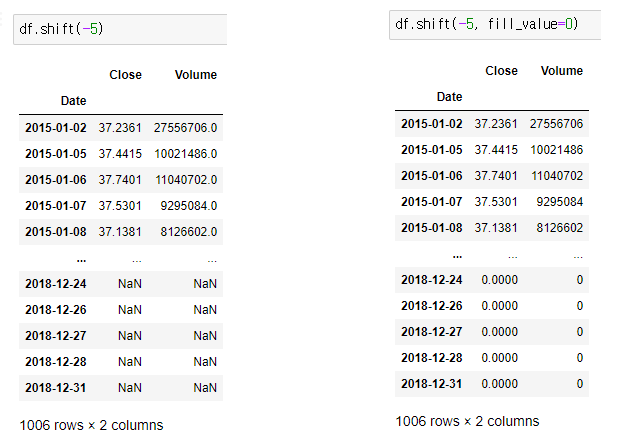
- df.shift(int형-양수일때) : 입력한 int 데이터 수만큼 앞에서 뒤로 밀리며 NaN으로 채워짐
- df.shift(int형-음수일때) : 입력한 int 데이터 수만큼 뒤에서 앞으로 밀리며 NaN으로 채워짐
- 밀린 수 만큼 NaN으로 채워지는 것이 싫고 특정한 값으로 채우고 싶다면 fill_value 인자 사용

- 뒤에서 앞으로 데이터를 5칸 밀고, 비워진 컬럼에 0으로 채움 → df.shift(-5, fill_value=0)
다. shift 인자 (periods=int, freq=str)
- 모든 데이터의 인덱스를 정해진 일자 만큼 이동 시킬 때 사용

3-3. 시간 빈도 집계 - rolling
가. rolling 설명
- 일종의 시간 빈도를 기반으로 집계를 하는 groupby와 유사한 기능
- 일일 데이터를 가져와 월 별 데이터로 샘플링하거나, 월 평균/합계를 낼 수 있음
나. rolling 인자 (window)
- Rolling은 일종의 기간의 ‘창’을 생성하는 것으로 집계함수와 같이 사용함. 해당 날짜를 포함하여 입력으로 받은 window 인자 수만큼 앞의 날짜에 대한 수치를 가져와 하나로 묶는 역할을 함
다. rolling 활용
예 ) 7일간의 섹션을 살펴본 후, 평균을 알고 싶을 때

라. rolling 활용 시각화
예 ) 전체 데이터의 종가 시각화

예 ) 전체 데이터를 7일의 섹션으로 나누어 해당 종가 평균의 시각화
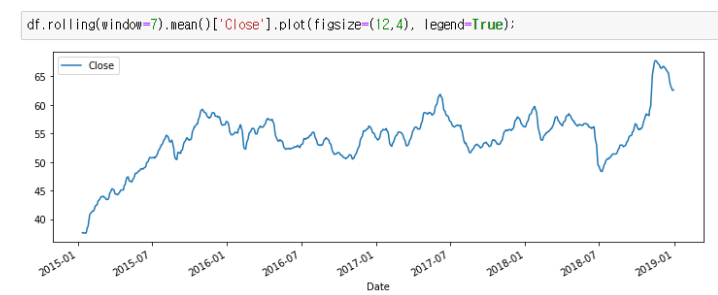
예 ) 위의 전체 데이터와, 7일 섹션 평균 종가 시각화

예 ) 위의 전체 데이터와 30일 섹션 평균 종가 시각화

- window크기의 창이 작아질수록 원본 데이터에 들어 맞는 고수준의 추세
- window크기의 창이 커지면 일반적인 추세를 보여줌
3-4. 시계열 누적 집계 - expanding
가. expanding 설명
- Rolling 창에 해당하는 날짜 값을 계산하는 대신, 시계열의 시작점부터 모든 것을 계산에 넣고 싶을때(모든 시점)
- 데이터 길이가 충분치 않을 때 데이터를 확장해가며 학습, 테스트 데이터를 추출할 때 사용 가능

나. expanding 인자
- min_periods 를 기준으로 누적하면서 수치화함
다. expanding 활용
예) 지난 7일 동안의 평균을 계산하는 대신, 모든 이전 데이터를 확장된 평균 집합에서 계산
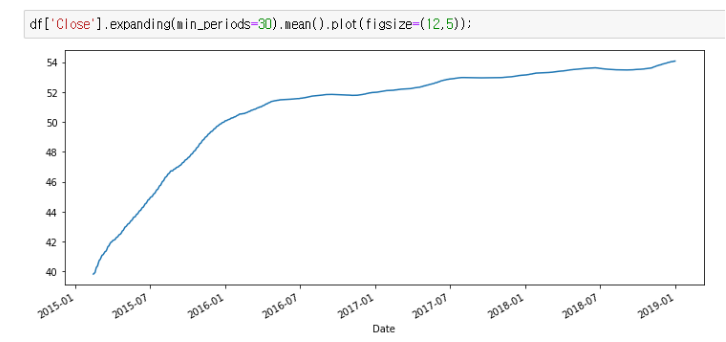
- 오른쪽 상단에 위치한 마지막 지점은 전체 데이터의 모든 행에 대한 집계임
'나혼빅(나혼자빅데이터) > 시계열데이터' 카테고리의 다른 글
| [시계열 데이터] 03. 시계열의 기본 특성(시계열 데이터 정의, 예제, 시계열데이터 구분, 분석 목적, 구성요소) (0) | 2022.03.17 |
|---|---|
| [시계열 데이터] 02. 시계열 데이터 시각화(autoscale, WeekdayLocator, DateFormatter) (0) | 2022.03.12 |